






Estudo do CINE torna aprendizado de máquina mais preciso na predição de propriedades de materiais

Os programas computacionais de aprendizado de máquina se destacam de todos os outros por terem a capacidade de aprender a partir da experiência, ou seja, a partir da interação com um conjunto de dados. Quanto maior a experiência, melhor é o desempenho desses programas ou modelos na tarefa para a qual foram criados. Contudo, eles nem sempre funcionam à perfeição. Erros acontecem, e poder detectá-los e resolvê-los é essencial.
Uma equipe de pesquisadores do CINE analisou os erros de um modelo de aprendizado de máquina criado para predizer propriedades físico-químicas de um grupo de materiais. “Os resultados apresentados podem tornar o uso de métodos de aprendizado de máquina na Ciência de Materiais mais assertivo e menos custoso”, diz Luis Cesar de Azevedo, um dos autores do artigo que reporta o estudo.
De fato, existe um interesse crescente no uso de ferramentas de aprendizado de máquina com o objetivo de encontrar materiais ou moléculas que tenham propriedades desejadas, de modo que possam cumprir com eficiência determinadas funções em dispositivos ou sistemas. No programa de Ciência Computacional de Materiais e Química (CMSC) do CINE, trabalhos sobre aprendizado de máquina vem sendo realizados com o objetivo de enfrentar a necessidade de desenvolver ou encontrar materiais eficientes para a geração e armazenamento de energia.
Para explorar o conjunto praticamente infinito de moléculas possíveis, métodos experimentais são impensáveis e métodos computacionais tradicionais não são suficientes, pois são relativamente demorados e, portanto, caros. Para se ter uma ideia, enquanto simular uma única molécula por um método convencional como a Teoria do Funcional da Densidade pode levar alguns dias, analisar dezenas de milhares de compostos por aprendizado de máquina pode tomar poucos segundos.
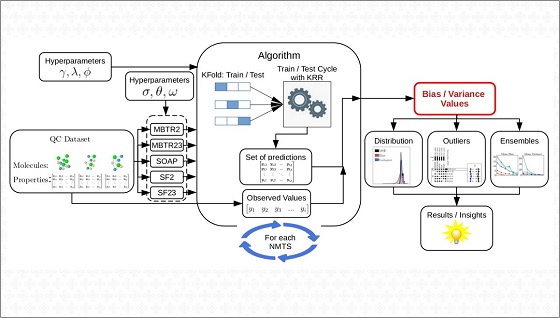
Para isso, é necessário desenvolver um algoritmo (um conjunto de instruções computacionais) e utilizar uma base de dados previamente obtida pela comunidade científica por métodos experimentais ou teóricos, como a que foi usada no estudo do CINE, que reúne dados de mais de 133 mil moléculas. O algoritmo deve, então, fazer seu treinamento, interagindo com os dados e reconhecendo padrões. O resultado dessa experiência é um modelo que será capaz de predizer as propriedades de materiais e moléculas que não constavam na base de dados inicial.
“Apesar de existirem modelos com uma alta acurácia média em alguns domínios, esses modelos podem cometer erros discrepantes (outliers) para algumas moléculas”, explica Luis César, que é membro do CMSC no CINE. “Este trabalho demonstrou que uma visão detalhada do erro, decompondo-o em erros sistemáticos (viés) e aleatórios (variância), pode mostrar características específicas do desempenho de predição”, completa. O trabalho também identificou que a maioria dessas imprecisões acontece com moléculas planares (aquelas que possuem ângulos mais abertos e maior distância entre seus átomos). Felizmente, o artigo mostrou que é possível reduzir os erros utilizando uma combinação de modelos de aprendizado de máquina (ensemble) para predizer as propriedades dos materiais. Além disso, segundo os autores, ao preparar o treinamento do algoritmo é necessário realizar uma seleção mais criteriosa dos dados e dos descritores (os valores computacionais usados para descrever as moléculas do banco de dados).
Este estudo foi realizado dentro da pesquisa de mestrado em Ciência da Computação que Luis Cesar está realizando na UFABC com a orientação do professor Ronaldo C. Prati (UFABC). O trabalho contou com a colaboração de outros membros do CINE, os professores Juarez L. F. Da Silva (IQSC-USP) e Marcos G. Quiles (UNIFESP), e o doutorando Gabriel A. Pinheiro (UNIFESP).
Referência do artigo científico: Systematic Investigation of Error Distribution in Machine Learning Algorithms Applied to the Quantum-Chemistry QM9 Data Set Using the Bias and Variance Decomposition. Luis Cesar de Azevedo, Gabriel A. Pinheiro, Marcos G. Quiles, Juarez L. F. Da Silva, and Ronaldo C. Prati. J. Chem. Inf. Model. 2021. https://doi.org/10.1021/acs.
Autores do artigo que são membros do CINE: Luis Cesar de Azevedo (mestrando na UFABC), Gabriel A. Pinheiro (doutorando na UNIFESP), Marcos G. Quiles (professor na UNIFESP), Juarez L. F. Da Silva (professor no IQSC-USP) e Ronaldo C. Prati (professor na UFABC).
Contato

Luis Cesar de Azevedo
UFABC - Brasil